Recently, a client HTML site (built with Adobe Dreamweaver) that showed up on page one of a Google search for a targeted keyword group simply “disappeared”. Really, I typed in the keywords and it would not show up in the search results – all the way down to page 10 and beyond! In fact, I typed in the domain name in the Google search box and it would not show up!
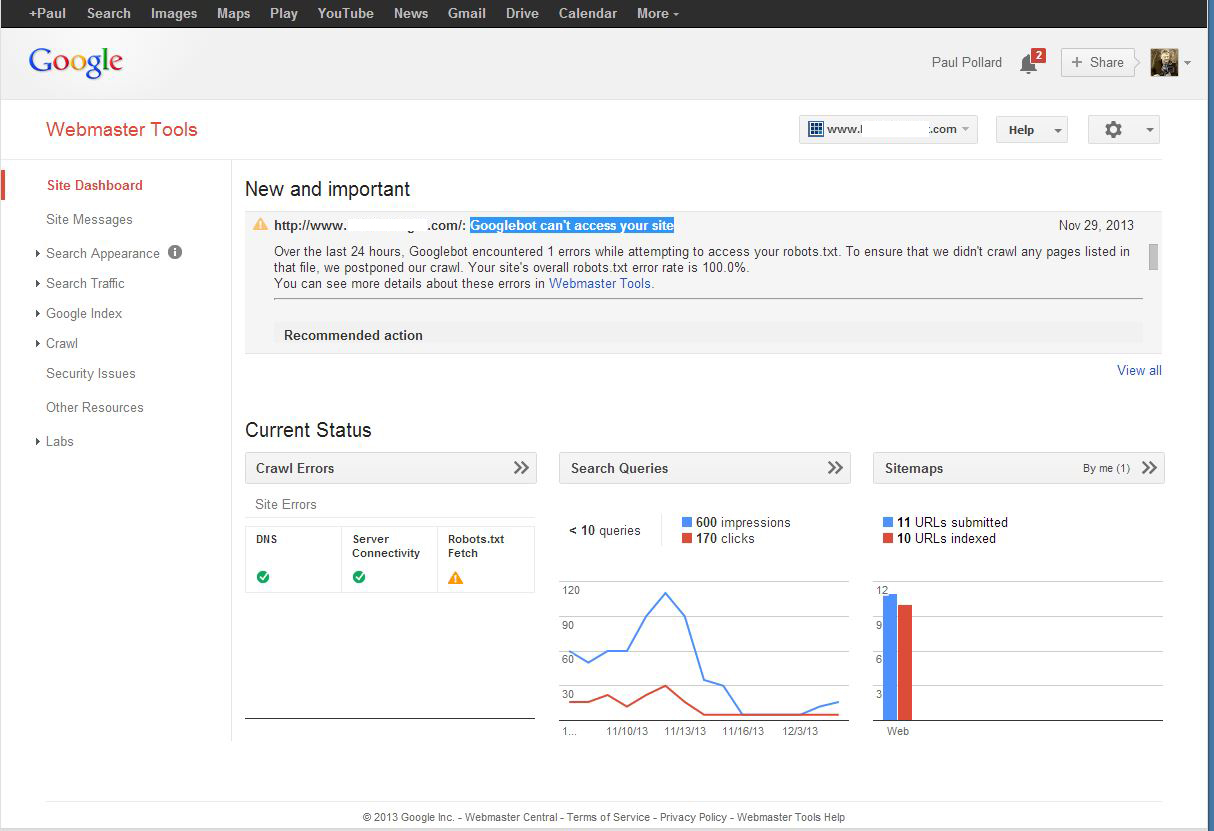
Frantic, I went to Bing and Yahoo, and there it was on page one of the search results. That was some relief! Nonetheless, I had to figure out the problem with Google. So I went to my Google Webmaster’s Tool Home and began examining the site dashboard. Under the Crawl Stats section, there were a few line graphs that represented Googlebot’s crawl activity. I noticed that in early November, the activity had flat-lined – like it had died! And, there was a message stating that “Google couldn’t crawl your site because we were unable to access your site’s robot.txt file.”
Now that was confusing because I had never before had a robot.txt file on the site. As an HTML site, I had always included the code <meta name=”robots” content=”index,follow”> in the head tags. I had learned to put that code in to make the site crawled and indexed by the various search engines.
So I immediately did some research to see what had changed and what I needed to do to resolve the situation.
Amazingly, it appeared lot of people had been having the same problem in 2013 – it was a relatively new phenomenon. But no where could I find a solution. I called tech support on my hosting service. They said they had heard about it, but they did not have a solution. I did more research and called back tech support – no solution. Then again, I did more research and called back tech support again. This time I got a guy that seemed to be interested in figuring it out. And that encouraged me. And he tried tweaking all the background domain configuration with no results.
But then it occurred to me, if Google says it can’t find a robots.txt file, then why not create one? So I suggested that to the tech guy and that’s where his savvy came in cause he had done that before and he created a robots.txt file with the code:
User-agent: *
Disallow:
And we uploaded it to the server. And then from my Google Webmaster Tools under the Crawl section, I used the “Fetch as Google” tool and directed it to the URL with the robot.txt file. Then I clicked on the red “Fetch” button and waited for the results – it said “denied by robots.txt. I tried several times with the same result. I began to feel kinda down and decided to just leave it alone.
But a few hours later, I guess my determination kicked in and I went back and looked at it again. And, then I clicked on the red “Fetch” button and the hand on the little time clock icon turned as before, but suddenly instead on “denied”, I got a green check button and the word “Success”! Now this was something.
You have to wait on Google to do it’s background work!
I went ahead and re-submitted a site index. Then I waited a day, and one URL came up in the Google search results. And on the second day, my site was back on page one!
It was really tough and challenging trying to figure out this one, but I did it with the help of my hosting tech support!